
Stack 和 Queue 絕對是資料結構中不可以錯過的一種容器,不只用於資料結構中這兩個字更廣泛出現在整個電腦科學的應用當中,從記憶體的組成、網路間的溝通到各種程式框架中或多或少都會看到他的影子。這兩種容器主要的特性是在於他們存取資料時隱含的先後順序不一樣(如下圖所示),Stack 提供同一個入口與出口,先被加入的元素會比較晚被取出,這種特性稱為「FILO(First In Last Out)」。Queue 是與前者相反的「FIFO(First In First Out)」的特性,也就是說它提供分別兩個入口與出口,從入口先被加入的元素會從出口比較早被取出。
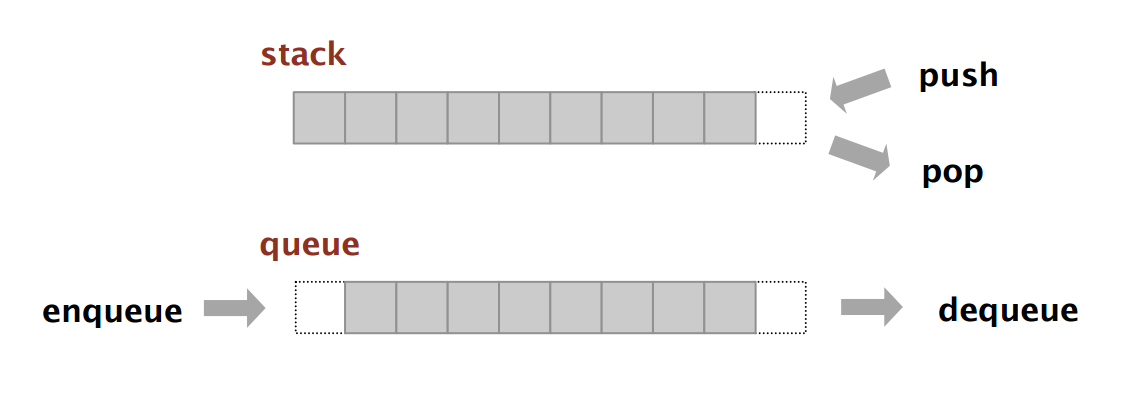
更多細節可以參考 Algorithms - Stacks and Queues 內文。在前三天的刷題實戰中,我們一起體驗幾題關於 Stack 和 Queue 的練習:
這三題是延續至前一段的題目,他們都根據鏈結串列(Linked List)或樹(Tree)的特性採取的常用的遞迴法。從「遞迴法」的概念延伸,導入「堆疊(Stack)」的抽象資料結構,將原本一層一層的遞迴呼叫轉化為 FILO(First In Last Out) 的儲存順序。為什麼會這樣想呢?其實遞迴法本來的呼叫概念就是執行到一半,先跳到下一層完成後再回來繼續執行,本質上也是一種 FILO 的順序。差別只是把原本由作業系統管理的遞迴,我們利用 Stack 性質來管理而已。
二元樹因為其非線性的結構,因爲每一個節點可能會有左/右分支而有不同的先後順序找法,這個過程稱為遍歷(Traverse)。這個題目定義的一種以階層為主的遍歷,因此我們必須要探訪每一個點的同時也滿足題目要求的先後順序。因此在這個題目中,我們分別示範如何用「窮舉迭代」、「用 Stack 暫存資料」和「用 Queue 暫存資料」三種方法時實現。
這兩題是一組經典的題組,要求用 Queue 和 Stack 互相實作。這兩種是存取方向不同的抽象資料結構,不會限定內內部如何實作,只要最終結果能夠符合該結構的性質與方法即可,常見的方法可以利用陣列、陣列串鏈來實作。而這個題目比較特別的是,要求只能夠用 Stack 與 Queue 兩個結構相互實作,在實作上就需要對這他們有更多的熟悉才能夠進一步運用。
資料結構(Data Structure)是由「資料」與「結構」兩個字組成,「資料」是指由多個元素所組成的有限集合,這些元素的組合關係稱為「結構」。換句話說,就是「一組資料在程式當中的儲存/組織方式」,有時候我們也會稱為容器(Container)或集合(Collection)。
你可能會從不同的來源看到不同的資料結構分類:


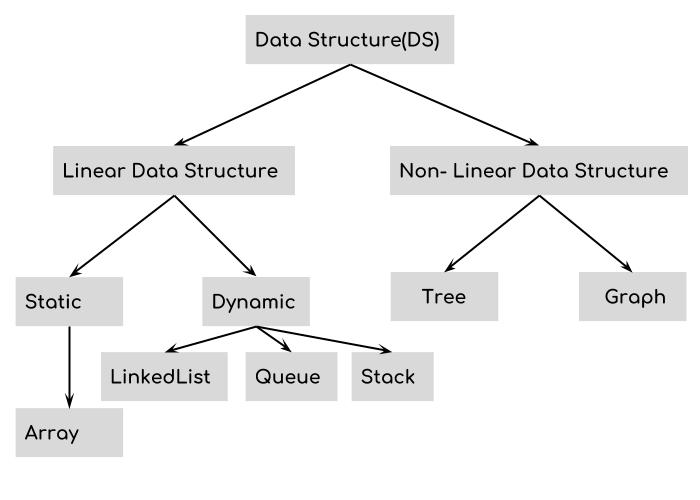
以上三張圖分別來源:Fundamental Data Structures and Algorithms in C#、Data Structure Interview Questions、DS introduction,有興趣也可以去看看原文。
除了「陣列與列表」、「物件與字典」這些基本的容器之外,在不同的程式語言也都有提供其他的資料結構可以使用,或是你可以利用現有的容器組裝出不同的資料結構。我們在前幾天用到的「Set(集合)」和「Map」就是,過去我們可能會強調邏輯運算的思維(也就是比較複雜的迴圈跟判斷),不過當你掌握不同語言提供的容器、善用資料結構特性也能夠讓你寫出更精簡更優化的程式碼。
從鏈結串列(Linked List)到樹(Tree)或二元搜尋樹(BST,Binary Search Tree),是一種從線性到非線性的概念。線性指的是只會有下一個可能,終究只會有一條路徑;非線性的話則可能有不同的分岔,可能會產生出兩條以上的可能路徑。比起大部分程式語言內建的陣列或物件來說,鏈結串列和樹更容易卡關,也增加了對於資料結構的一絲恐懼感。對於一個容器「建立」、「新增」、「刪除」或「查詢」都是基本的操作,不過當遇到複雜的鏈結串列或樹結構,就多了一層的挑戰。
最後回到 Stack 與 Queue 這兩種資料結構容器,他們不同於前面幾種關注在「存」的資料結構,Stack 與 Queue 更在意的是「存取」當中的先後順序。如果有一連串的元素組成,先存入的元素,應該先被取出還是後取出呢?這就是 Stack 跟 Queue 所考慮的點,搭配上這兩種結構更能用應用於不同的使用情境。
最後一段稍微來討論關於 Stack 與 Queue 的定義與實作:
根據 維基百科 的定義:Stack(堆疊,又稱為棧或堆棧),是電腦科學中一種特殊的串列形式的抽象資料型別,其特殊之處在於只能允許在連結串列或陣列的一端加入資料和輸出資料的運算。由於堆疊資料結構只允許在一端進行操作,因而按照後進先出(LIFO, Last In First Out)的原理運作。
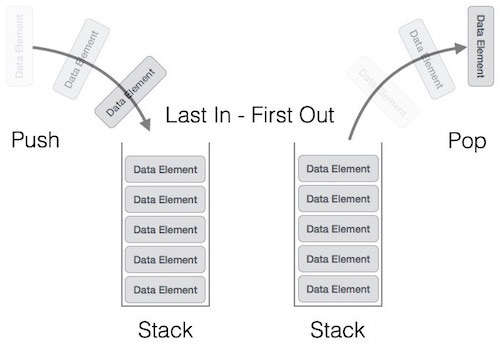
根據 維基百科 的定義:Queue(佇列,又稱為隊列),是先進先出(FIFO, First-In-First-Out)的線性容器,佇列只允許在後端進行插入操作,在前端進行刪除操作。佇列的操作方式和堆疊類似,唯一的區別在於佇列只允許新數據在後端進行添加。

嗨,大家好!我是維元,一名擅長網站開發與資料科學的雙棲工程師,斜槓於程式社群【JSDC】核心成員及【資料科學家的工作日常】粉專經營。目前在 ALPHACamp 擔任資料工程師,同時也在中華電信、工研院與多所學校等單位持續開課。擁有多次大型技術會議講者與競賽獲獎經驗,持續在不同的平台發表對 #資料科學、 #網頁開發 或 #軟體職涯 相關的分享,邀請你加入 訂閱 接收最新資訊。


 iThome鐵人賽
iThome鐵人賽